go函数和方法调用
目标
- 了解go函数调用规约
- 了解go语言汇编基础
- 掌握通过汇编分析go语言原理的方法
go函数调用规约
- 通过堆栈传递参数,参数从左到右的顺序在栈上右低地址向高地址排列;
- 函数返回值通过堆栈传递并由调用者预先分配内存空间;
- 调用函数时都是传值,接收方会对入参进行复制再计算;
拆解一个go程序
思考一下下面这段 Go 代码:
1 | |
将这段代码编译到汇编:
1 | |
1 | |
解剖main
1 | |
0x0000: 当前指令相对于当前函数的偏移量。TEXT "".add:TEXT指令声明了"".main是.text段的一部分,并表明跟在这个声明后的是函数的函数体。 在链接期,""这个空字符会被替换为当前的包名: 也就是说,"". main在链接到二进制文件后会变成main.main。(SB):SB是一个虚拟寄存器,保存了静态基地址(static-base) 指针,即我们程序地址空间的开始地址。"".main(SB)表明我们的符号位于某个固定的相对地址空间起始处的偏移位置 (最终是由链接器计算得到的)。换句话来讲,它有一个直接的绝对地址: 是一个全局的函数符号。- $24-0: $24 代表即将分配的栈帧大小;而 $0 指定了调用方传入的参数大小。
1 | |
- SP是栈顶指针寄存器,SUBQ 表示减操作;栈内存是向下增长,此操作相当于给函数分配24字节栈帧;
- BP保存了当前函数栈帧栈底的地址,一开始需要将旧的BP值保存。然后将新的栈帧地址赋值给BP寄存器;
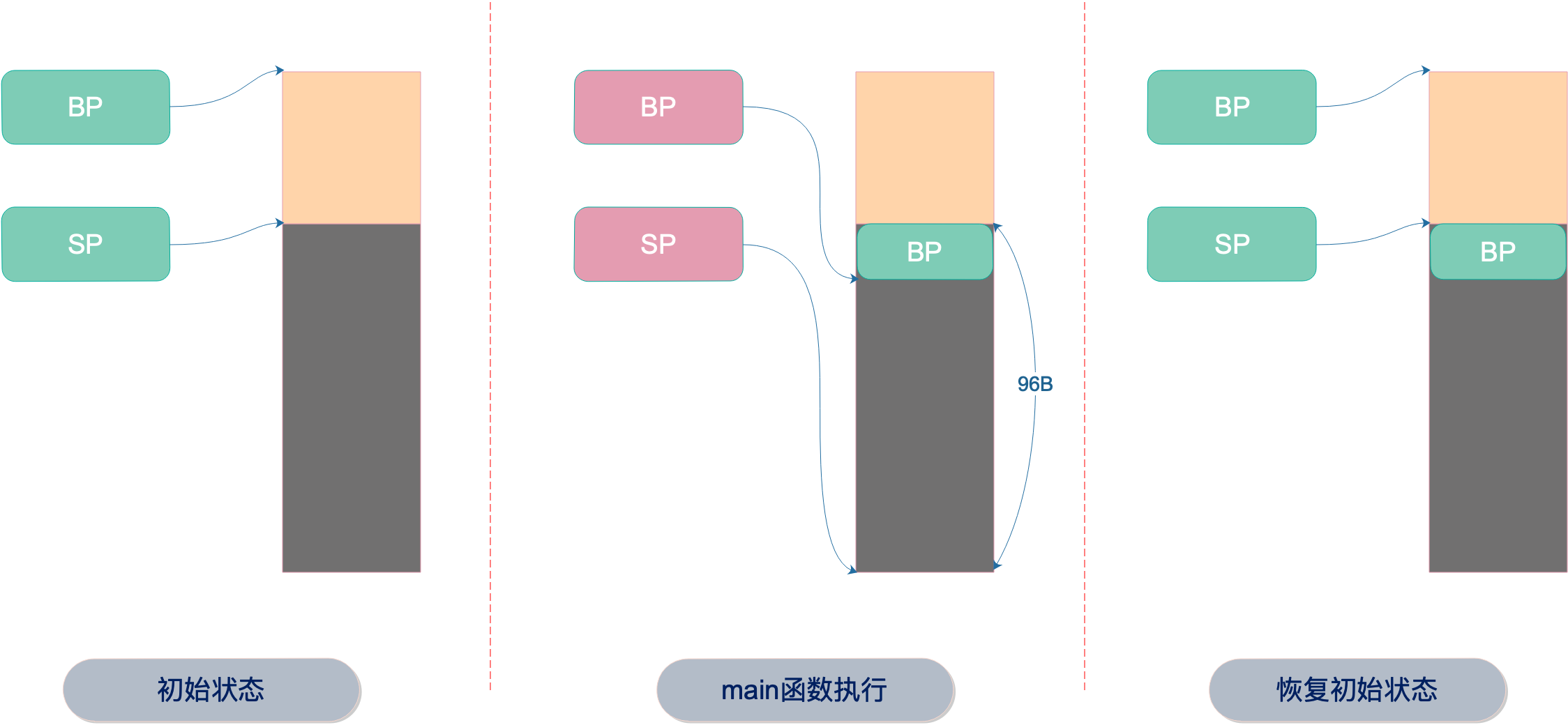
main 作为调用者,通过对SP寄存器做减法,将其栈帧大小增加了 24 个字节,这 24 个字节中:
- 8 个字节(
16(SP)-24(SP)) 用来存储旧的帧指针 (这是一个实际存在的寄存器)的值,以支持栈的展开和方便调试 - 1+3 个字节(
12(SP)-16(SP)) 预留出的给第二个返回值 (bool) 的空间,除了类型本身的 1 个字节,在amd64平台上还额外需要 3 个字节来做对齐 - 4 个字节(
8(SP)-12(SP)) 预留给第一个返回值 (int32) - 4 个字节(
4(SP)-8(SP)) 预留给传入参数b (int32) - 4 个字节(
0(SP)-4(SP)) 预留给传入参数a (int32)
1 | |
137438953482 这个值看起来像是随机的垃圾值,实际上这个值对应的就是 10 和 32 这两个 4 字节值,它们两被连接成了一个 8 字节值。二进制位图如下:
1 | |
1 | |
CALL指令可以理解为PUSH+JMP。PUSH指令将函数返回地址(0x30)保存在栈帧的顶部,然后JMP到add函数起始指令地址处。- 注意因为
CALL指令会将函数的返回地址(8 字节值)也推到栈顶;所以每次我们在add函数中引用SP寄存器的时候还需要额外偏移 8 个字节!
指令执行到此会进入add函数。下面就来具体剖析一下add函数
解剖add
1 | |
"".b+12(SP)和"".a+8(SP)分别指向栈的低 12 字节和低 8 字节位置。.a和.b是分配给引用地址的任意别名;尽管 它们没有任何语义上的含义 ,但在使用虚拟寄存器和相对地址时,这种别名是需要强制使用的。- 取出参数a和b的值放置到通用寄存器AX、CX中
- 第一个变量
a的地址并不是0(SP),而是在8(SP);这是因为调用方通过使用CALL伪指令,把其返回地址保存在了0(SP)位置。
1 | |
ADDL指令进行加法操作,L 这里代表 Long,4 字节的值,其将保存在AX和CX寄存器中的值进行相加,然后再保存进AX寄存器中。 这个结果之后被移动到"".~r2+16(SP)地址处,这是之前调用方专门为返回值预留的栈空间。"".~r2同样没什么语义上的含义。
1 | |
RET指令使在0(SP)寄存器中保存的函数返回地址被POP出栈,并跳回到该地址。- 和
CALL指令相反,RET指令为POP+JMP操作。
总之,下面是 main.add 即将执行 RET 指令时的栈的情况。
1 | |
返回主函数main
add函数执行RET回到了main函数0x30指令处:
1 | |
最后
- 将帧指针下降一个栈帧的大小
- 将栈收缩 24 个字节,回收之前分配的栈空间
- 请求 Go 汇编器插入子过程返回相关的指令
栈和栈分裂
栈
由于 Go 程序中的 goroutine 数目是不可确定的,并且实际场景可能会有百万级别的 goroutine,runtime 必须使用保守的思路来给 goroutine 分配空间以避免吃掉所有的可用内存。
也由于此,每个新的 goroutine 会被 runtime 分配初始为 2KB 大小的栈空间。
随着一个 goroutine 进行自己的工作,可能会超出最初分配的栈空间限制(就是栈溢出的意思)。 为了防止这种情况发生,runtime 确保 goroutine 在超出栈范围时,会创建一个相当于原来两倍大小的新栈,并将原来栈的上下文拷贝到新栈上。 这个过程被称为 栈分裂(stack-split),这样使得 goroutine 栈能够动态调整大小。
栈分裂
为了使栈分裂正常工作,编译器会在每一个函数的开头和结束位置插入指令来防止 goroutine 栈溢出。 像我们本章早些看到的一样,为了避免不必要的开销,一定不会爆栈的函数会被标记上 NOSPLIT 来提示编译器不要在这些函数的开头和结束部分插入这些检查指令。
我们来看看之前的 main 函数,这次不再省略栈分裂的前导指令:
1 | |
可以看到,栈分裂(stack-split)前导码被分成 prologue 和 epilogue 两个部分:
- prologue 会检查当前 goroutine 是否已经用完了所有的空间,然后如果确实用完了的话,会直接跳转到后部。
- epilogue 会触发栈增长(stack-growth),然后再跳回到前部。
这样就形成了一个反馈循环,使我们的栈在没有达到饥饿的 goroutine 要求之前不断地进行空间扩张。
Prologue
1 | |
TLS 是一个由 runtime 维护的虚拟寄存器,保存了指向当前 g 的指针,这个 g 的数据结构会跟踪 goroutine 运行时的所有状态值。
看一看 runtime 源代码中对于 g 的定义:
1 | |
我们可以看到 16(CX) 对应的是 g.stackguard0,是 runtime 维护的一个阈值,该值会被拿来与栈指针(stack-pointer)进行比较以判断一个 goroutine 是否马上要用完当前的栈空间。
因此 prologue 只要检查当前的 SP 的值是否小于或等于 stackguard0 的阈值就行了,如果是的话,就跳到 epilogue 部分去。
Epilogue
1 | |
epilogue 部分的代码就很直来直去了: 它直接调用 runtime 的函数,对应的函数会将栈进行扩张,然后再跳回到函数的第一条指令去(就是指 prologue部分)。
在 CALL 之前出现的 NOP 这个指令使 prologue 部分不会直接跳到 CALL 指令位置。在一些平台上,直接跳到 CALL 可能会有一些麻烦的问题;所以在调用位置插一个 noop 的指令并在跳转时跳到这个 NOP 位置是一种最佳实践。
方法的调用
之前讲解的是函数的调用,go语言程序中存在更多的是对方法的调用。对方法的调用(无论 receiver 是值类型还是指针类型)和对函数的调用是相同的,唯一的区别是 receiver 会被当作第一个参数传入。
1 | |
指针receiver
receiver 是通过 adder := Adder{id: 6754} 来初始化的:
1 | |
上述指令初始化了结构体,栈内存的摆列顺序从低地址到高地值为:函数参数->函数返回值->局部变量(这里省略了return address 和BP)。在这里这个结构体算是一个局部变量,因此被放在了栈的高地址处28(SP)。
1 | |
然后对结构体取指针,现在AX存的就是receiver。前面提到receiver要作为第一个参数,于是将AX放在栈的(SP)处,后面的指令就和函数的调用类似了,初始化其他的参数。并使用CALL指令调用"".(*Adder).AddPtr
值receiver
当 receiver 是值类型时,生成的代码和上面的类似。
1 | |
因为 receiver 是值类型,且编译器能够通过静态分析推测出其值,这种情况下编译器认为不需要对值从它原来的位置(28(SP))进行拷贝了: 相应的,只要简单的在栈上创建一个新的和 Adder 相等的值,把这个操作和传第二个参数的操作进行捆绑,还可以节省一条汇编指令。